

Earlier in our previous article Improve efficiency of your SELECT queries we discussed ways to profile and optimize the performance of SELECT queries. However, to write complex yet efficient SQL queries, there is a thing to remember about.
The RDBMS query interpreter is pretty good at applying optimizations, but it does not know exactly what you want. Sometimes, to help it, you have to be extra careful with what structure of query you are using. Let us consider different database schema for this example:
CREATE TABLE pizza_recipe (
id serial PRIMARY KEY,
name text UNIQUE NOT NULL
);
CREATE TABLE pizza_crust (
id serial PRIMARY KEY,
name text UNIQUE NOT NULL
);
CREATE TABLE pizza_restaurant (
id serial PRIMARY KEY,
name text UNIQUE NOT NULL
);
CREATE TABLE pizza_takeout (
id serial PRIMARY KEY,
pizza_recipe_id integer references pizza_recipe(id) NOT NULL,
pizza_crust_id integer references pizza_crust(id) NOT NULL,
pizza_restaurant_id integer references pizza_restaurant(id) NOT NULL,
order_time timestamp DEFAULT current_timestamp,
address text NOT NULL
);
CREATE INDEX pizza_recipe_id__pizza_takeout__idx ON pizza_takeout (pizza_recipe_id);
CREATE INDEX pizza_crust_id__pizza_takeout__idx ON pizza_takeout (pizza_crust_id);
CREATE INDEX pizza_restaurant_id__pizza_takeout__idx ON pizza_takeout (pizza_restaurant_id);
INSERT INTO pizza_recipe (name)
VALUES
('Pepperoni'),
('Texas'),
('Margherita');
INSERT INTO pizza_crust (name)
VALUES
('Ordinary'),
('Cheeze'),
('Sausage');
INSERT INTO pizza_restaurant (name)
VALUES
('Restaurant 1'),
('Restaurant 2'),
('Restaurant 3');
INSERT INTO pizza_takeout (pizza_recipe_id, pizza_restaurant_id, pizza_crust_id, address)
VALUES
(1, 1, 1, ''),
(1, 1, 1, ''),
(1, 1, 2, ''),
(1, 1, 3, ''),
(1, 2, 1, ''),
(1, 2, 1, ''),
(1, 2, 2, ''),
(1, 2, 3, ''),
(1, 3, 1, ''),
(1, 3, 1, ''),
(1, 3, 2, ''),
(1, 3, 3, ''),
(2, 3, 1, ''),
(2, 3, 1, ''),
(2, 3, 2, ''),
(2, 3, 3, ''),
(3, 3, 1, ''),
(3, 3, 1, ''),
(3, 3, 2, ''),
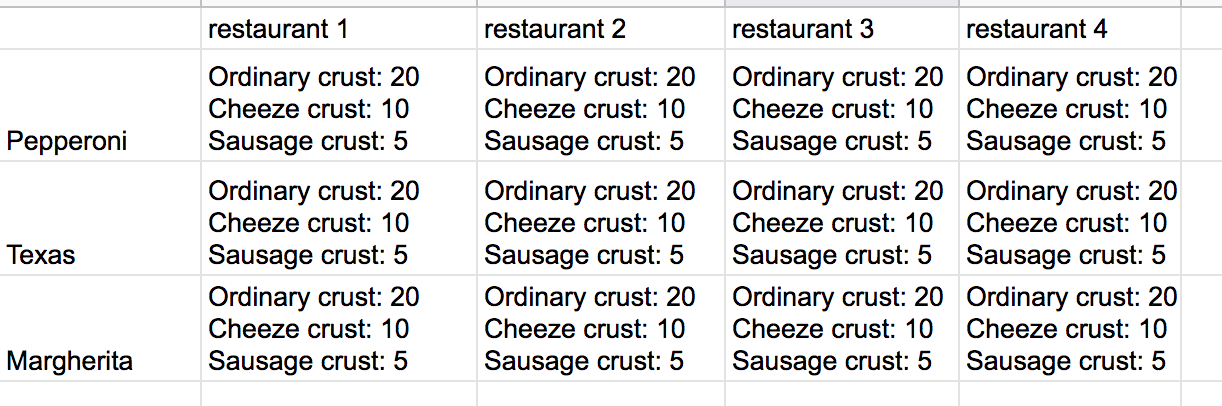
(3, 3, 3, '');Here we have a pizza restaurant network. Its schema consists of a kind of pizza (pizza_recipe), crust (pizza_crust), restaurant (pizza_restaurant), and order for pizza delivery (pizza_takeout). Suppose we need to implement the report showing a count of pizza orders in the following restaurants, with particular kind and particular crust. It should look like this:
There are multiple ways to form a data structure that will look like this on the frontend, but I find the following approach the most suitable. Here is the API response schema:
{
"restaurant_list": [
{
"restaurant_id": 1,
"restaurant_name": "restaurant 1",
"recipe_list": [
{
"recipe_id": 1,
"recipe_name": "Pepperoni",
"crust_list": [
{
"crust_id": 1,
"recipe_id": 1,
"restaurant_id": 1,
"crust_name": "Ordinary crust",
"count": 20
},
{
"crust_id": 2,
"recipe_id": 1,
"restaurant_id": 1,
"crust_name": "Cheeze crust",
"count": 10
},
{
"crust_id": 3,
"recipe_id": 1,
"restaurant_id": 1,
"crust_name": "Sausage crust",
"count": 5
}
]
},
...
]
},
...
]
}One of its advantages is that we are able to get such a response schema by using only database queries and its connection engine in your programming language. For example, Python gets JSON objects from the database and transforms them into a JSON response pretty efficiently.
However, there are two ways to implement it. The first one is more intuitive and straightforward. It includes selecting top-level entities and getting its child data via a hierarchy of subqueries. It may be implemented like this:
SELECT
*
FROM pizza_restaurant
LEFT OUTER JOIN LATERAL (
SELECT
pizza_restaurant_id,
json_agg(pizza_recipe_agg) AS pizza_recipe_list
FROM (
SELECT
pizza_recipe.name AS pizza_recipe_name,
pizza_recipe.id AS pizza_recipe_id,
pizza_restaurant.id AS pizza_restaurant_id,
pizza_crust_list_agg.pizza_crust_list
FROM pizza_recipe
LEFT OUTER JOIN LATERAL (
SELECT
pizza_crust_list_agg.pizza_recipe_id,
pizza_crust_list_agg.pizza_restaurant_id,
json_agg(pizza_crust_list_agg) AS pizza_crust_list
FROM (
SELECT
pizza_crust.name AS pizza_crust_name,
pizza_crust.id AS pizza_crust_id,
pizza_recipe.id AS pizza_recipe_id,
pizza_restaurant.id AS pizza_restaurant_id,
pizza_takeout_agg.count
FROM pizza_crust
LEFT OUTER JOIN (
SELECT
COUNT(*) AS count,
pizza_recipe_id,
pizza_crust_id,
pizza_restaurant_id
FROM pizza_takeout
GROUP BY
pizza_recipe_id,
pizza_crust_id,
pizza_restaurant_id
) pizza_takeout_agg
ON pizza_crust.id = pizza_takeout_agg.pizza_crust_id
AND pizza_recipe.id = pizza_takeout_agg.pizza_recipe_id
AND pizza_restaurant.id = pizza_takeout_agg.pizza_restaurant_id
) pizza_crust_list_agg
GROUP BY pizza_crust_list_agg.pizza_recipe_id,
pizza_crust_list_agg.pizza_restaurant_id
) pizza_crust_list_agg
ON pizza_recipe.id = pizza_crust_list_agg.pizza_recipe_id
AND pizza_restaurant.id = pizza_crust_list_agg.pizza_restaurant_id
) pizza_recipe_agg
GROUP BY
pizza_restaurant_id
) pizza_restaurant_list_agg
ON pizza_restaurant.id = pizza_restaurant_list_agg.pizza_restaurant_id;And its EXPLAIN looks like this:
QUERY PLAN
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Nested Loop Left Join (cost=12.70..80251316.35 rows=1270 width=72)
-> Seq Scan on pizza_restaurant (cost=0.00..22.70 rows=1270 width=36)
-> Subquery Scan on pizza_restaurant_list_agg (cost=12.70..63189.99 rows=1 width=36)
Filter: (pizza_restaurant.id = pizza_restaurant_list_agg.pizza_restaurant_id)
-> GroupAggregate (cost=12.70..63189.97 rows=1 width=36)
Group Key: pizza_restaurant.id
-> Nested Loop Left Join (cost=12.70..63183.61 rows=1270 width=72)
-> Seq Scan on pizza_recipe (cost=0.00..22.70 rows=1270 width=36)
-> Subquery Scan on pizza_crust_list_agg (cost=12.70..49.72 rows=1 width=36)
Filter: (pizza_recipe.id = pizza_crust_list_agg.pizza_recipe_id)
-> GroupAggregate (cost=12.70..49.71 rows=1 width=40)
Group Key: pizza_recipe.id, pizza_restaurant.id
-> Result (cost=12.70..40.17 rows=1270 width=52)
One-Time Filter: (pizza_restaurant.id = pizza_restaurant.id)
-> Hash Left Join (cost=12.70..40.17 rows=1270 width=44)
Hash Cond: (pizza_crust.id = pizza_takeout_agg.pizza_crust_id)
-> Seq Scan on pizza_crust (cost=0.00..22.70 rows=1270 width=36)
-> Hash (cost=12.69..12.69 rows=1 width=12)
-> Subquery Scan on pizza_takeout_agg (cost=12.65..12.69 rows=1 width=12)
-> GroupAggregate (cost=12.65..12.68 rows=1 width=20)
Group Key: pizza_takeout.pizza_recipe_id, pizza_takeout.pizza_crust_id, pizza_takeout.pizza_restaurant_id
-> Sort (cost=12.65..12.66 rows=1 width=12)
Sort Key: pizza_takeout.pizza_crust_id
-> Bitmap Heap Scan on pizza_takeout (cost=8.63..12.64 rows=1 width=12)
Recheck Cond: ((pizza_restaurant.id = pizza_restaurant_id) AND (pizza_recipe.id = pizza_recipe_id))
-> BitmapAnd (cost=8.63..8.63 rows=1 width=0)
-> Bitmap Index Scan on pizza_restaurant_id__pizza_takeout__idx (cost=0.00..4.19 rows=5 width=0)
Index Cond: (pizza_restaurant_id = pizza_restaurant.id)
-> Bitmap Index Scan on pizza_recipe_id__pizza_takeout__idx (cost=0.00..4.19 rows=5 width=0)
Index Cond: (pizza_recipe_id = pizza_recipe.id)The lower rows are less important, what really interests us is the overall cost at line 3. The worst-case cost looks like this query could become a real bottleneck on large data samples. Let us think about why is it so slow.
The problem is that we have nested subqueries in this query. This means that on every combination of restaurant, pizza, and crust we will query database for pizza_takeout records. Let us try to write a query that will have a more predictable cost.
SELECT
pizza_restaurant.id AS pizza_restaurant_id,
pizza_restaurant.name AS pizza_restaurant_name,
json_agg(pizza_recipe_list_agg) AS pizza_recipe_list
FROM (
SELECT
pizza_recipe.id,
pizza_recipe.name,
pizza_crust_list_agg.pizza_restaurant_id,
json_agg(pizza_crust_list_agg) AS pizza_crust_list
FROM (
SELECT
pizza_crust.id AS pizza_crust_id,
pizza_crust.name AS pizza_crust_name,
pizza_takeout_agg.pizza_recipe_id,
pizza_takeout_agg.pizza_restaurant_id,
pizza_takeout_agg.count AS count
FROM (
SELECT
COUNT(*) AS count,
pizza_recipe_id,
pizza_crust_id,
pizza_restaurant_id
FROM pizza_takeout
GROUP BY
pizza_recipe_id,
pizza_crust_id,
pizza_restaurant_id
) pizza_takeout_agg
INNER JOIN pizza_crust
ON pizza_takeout_agg.pizza_crust_id = pizza_crust.id
) pizza_crust_list_agg
INNER JOIN pizza_recipe
ON pizza_crust_list_agg.pizza_recipe_id = pizza_recipe.id
GROUP BY
pizza_recipe.id,
pizza_crust_list_agg.pizza_restaurant_id
) pizza_recipe_list_agg
INNER JOIN pizza_restaurant
ON pizza_recipe_list_agg.pizza_restaurant_id = pizza_restaurant.id
GROUP BY pizza_restaurant.id
;And here is its output:
QUERY PLAN
-------------------------------------------------------------------------------------------------------------------------------------------------
HashAggregate (cost=157.70..160.20 rows=200 width=68)
Group Key: pizza_restaurant.id
-> Hash Join (cost=151.68..156.70 rows=200 width=100)
Hash Cond: (pizza_recipe_list_agg.pizza_restaurant_id = pizza_restaurant.id)
-> Subquery Scan on pizza_recipe_list_agg (cost=113.10..117.60 rows=200 width=68)
-> HashAggregate (cost=113.10..115.60 rows=200 width=72)
Group Key: pizza_recipe.id, pizza_takeout.pizza_restaurant_id
-> Hash Join (cost=106.55..111.60 rows=200 width=88)
Hash Cond: (pizza_takeout.pizza_recipe_id = pizza_recipe.id)
-> Hash Join (cost=67.98..72.50 rows=200 width=52)
Hash Cond: (pizza_takeout.pizza_crust_id = pizza_crust.id)
-> HashAggregate (cost=29.40..31.40 rows=200 width=20)
Group Key: pizza_takeout.pizza_recipe_id, pizza_takeout.pizza_crust_id, pizza_takeout.pizza_restaurant_id
-> Seq Scan on pizza_takeout (cost=0.00..19.70 rows=970 width=12)
-> Hash (cost=22.70..22.70 rows=1270 width=36)
-> Seq Scan on pizza_crust (cost=0.00..22.70 rows=1270 width=36)
-> Hash (cost=22.70..22.70 rows=1270 width=36)
-> Seq Scan on pizza_recipe (cost=0.00..22.70 rows=1270 width=36)
-> Hash (cost=22.70..22.70 rows=1270 width=36)
-> Seq Scan on pizza_restaurant (cost=0.00..22.70 rows=1270 width=36)
(20 rows)As you can see, the query build plan is shorter and the cost is dramatically smaller. Why is that? Looking closer into the second query, you can see that the main FROM is built around the selection of pizza_takeout records. This gives us the following advantages:
The query has the single reliable “backbone“ selection - pizza_takeout_agg, all the other data is joined to it;
This selection has the largest amount of records (compare the possible amount of pizza recipes to pizza orders), so it is most logical to get this data in the least amount of database queries as possible;
If for some reason, you will be having a separate table pizza_restaurant_order for storing data about people who visit your restaurant, and you will want to have unified statistics between orders and takeouts, you may apply UNION inside the pizza_takeout_agg, and you will have this report updated without major structure change;
This pizza example is designed to show that in SQL there are multiple ways to do something, and you want to be careful about choosing the most obvious one. Moreover, the example is pretty typical, so you may encounter something very similar if you are involved into some sort of Business Intelligence domain.
Conclusion
SQL SELECT queries are all about formulating a proper way to extract and arrange data. So, when writing a query, you should keep the data structure in mind, thinking about how different entities are connected and how expensive would it be to arrange them in a certain way. If it feels that selection is slow or might be slow on larger datasets - it is recommended to generate large data samples and profile query with EXPLAIN ANALYZE statements.
Subscribe for the news and updates
In the previous article, we learned about test analysis for a product in general, and now we are ready to go further and look at test analysis for specific features.

Tired of boring programming courses where you're forced to read thick textbooks and write code that's never used? Need a platform that makes learning fun and exciting? Then you're in the right place!

Protection of WEB App is of paramount importance and it should be afforded the same level of security as the intellectual rights or private property. I'm going to cover how to protect your web app.

For local project settings, I use old trick with settings_local file:try:from settings_local import \*except ImportError:passSo in settings_local.py we can override variables from settings.py. I didn't know how to supplement them. For example how to add line to INSTALLED_APPS without copying whole list.Yesterday I finally understood that I can import settings from settings_local:# settings_local.pyfrom settings import \*INSTALLED_APPS += (# ...)

There was a task to submit form with ajax, with server side validation of course. Obvious solution is to do validation and return json with erros. I didn't like idea of writing separate view for validation and then inserting errors in form html on client side. Especially since I already had a generic template for django form with errors display. In this article I'll describe how I solved the task.
Usually users' profiles are stored in single model. When there are multiple user types, separation is made by some field like user_type.Situation is a little more complicated when different data is needed for each user type.In this article I'll describe how I solve this task.