

Designing database architecture is a challenging task, and it gets even more difficult when your app keeps getting bigger. Here are several tips on how to manage your data structure in a more efficient way.
Get closely acquainted with the application domain
Every database table is meant to represent some sort of entity. So, a good start to designing a database schema is to become familiar with the application domain. This is even more crucial if the project exists in a state of rapidly changing requirements and an unclear scope.
As customers use applications to solve their business problems, all their feature requests will be based on processes specific to their particular industries. So, even if they do not request something yet, it is a good move to keep in mind how they do business and depict it in a database schema.
Let us consider an example. Our customer is a logistics company looking for a new application to track transportations. Their initial requirements are ways to track:
- Railway logistics
- Automobile logistics
- Shipping by sea.
These kinds of transportation may look entirely different and have different properties and varying logic around them, so it is easy to get disoriented and implement them as different entities unrelated in any way. However, it is possible that tracking all these transportations is needed to generate a single large report about the state of warehouses. This may come as a surprise to those unfamiliar with the application domain and can be costly if the database schema is not properly designed.
However, if the business analyst or developer has the experience of developing such systems before or gets closely acquainted with the business domain, there is a better chance of satisfying the customer.
Think about defining a “basic” entity
For some domains, it may be useful to distinguish a “basic” entity. For example, any logistical document in the system may be described as transportation of some commodity going from place A to place B with the dates of departure and arrival. Of course, other fields may differ dramatically for naval and railway transportation. However, if your application needs a global logistic report that involves all kinds of shipments, such an approach will prove to be very useful.
Another example of using a “basic” entity may be seen in the financial domain. There can be several different types of financial documents, but all of them have a sender, a receiver, a date, and finance accounts of revenue and expenditure. So, when designing reports including all finance entities, it is useful to have a single database table with all the necessary data.
The following ER diagram shows the possible architecture of a system based around financial entities, where they have common fields. With such a database schema it is convenient to build reports that include multiple different business objects. Invoices and payments are both inherited from the parent entity, which stores the most essential fields.
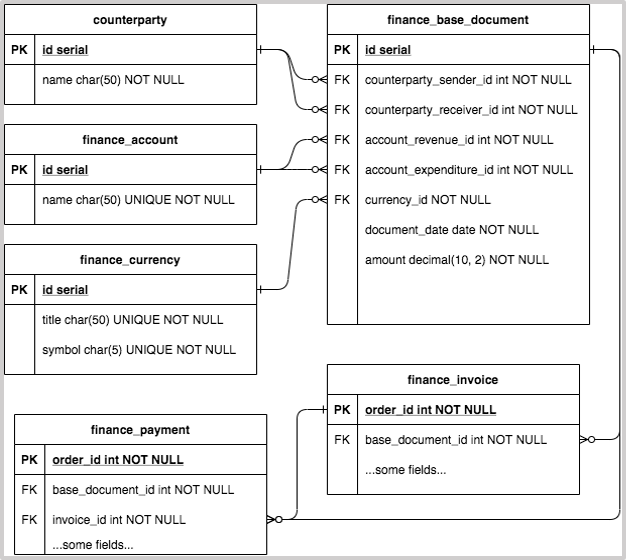
The most straightforward way to implement a database schema using such “basic” entities is describing a table for all basic fields, and then describing tables for each entity, all of them having foreign keys to the basic table. PostgreSQL also has its own table inheritance mechanism, but with some caveats, so be careful.
Be careful with “symmetric” object properties
It may be tempting to name your contract “sale/purchase” and your payment “incoming/outgoing,” as well as to have a single “other party” field, but be careful about it and think where the application might grow. Sometimes a system designed to be used by a single company may require the inclusion of contracts between two departments with proper display in reports.
Having statuses such as “incoming” and “outgoing” is perfectly fine if you are sure about the application’s scope and there are little chances of growth and requirement change. However, in some cases, it is reasonable to store information about both parties of the contract/invoice/logistics and simply deduce the “incoming/outgoing” type depending on the point of view.
scope and there are little chances of growth and requirements change. However, in some cases, it is reasonable to store information about both parties of contract/invoice/logistics and simply deduce the “incoming/outgoing” type depending on the point of view.
Use precise data types for essential numeric data
It may be an obvious tip, but sometimes it gets ignored and backfires. Numeric values such as money or amount in tons must be stored in data types that ensure exactness.
Moreover, in such data types it is usually possible to set a specific amount of digits after the decimal point. This may help enforce some constraints to data format. The examples of using this approach may be:
the decimal point. This may help to enforce some constraints to data format. The examples of using this approach may be:
- Storing volume in tonnes, allowing only three digits after the decimal point, which will represent amount in tonnes and kilograms
- Storing monetary amounts with two digits after the decimal point
- Storing currency exchange rates with X digits after the decimal point, since in some domains exchange rates are stored with four or six decimal placesUsing PostgreSQL as an example, here is more information about the subject.
Using PostgreSQL as an example, here is more information about the subject.
Use SQL views as a way to reuse business logic
SQL view is a powerful tool for describing and reusing business logic. Basically, it is a query stored under a certain name, and the query is executed when the view's name is referenced. We are not currently looking at materialized views; these are an even more powerful tool for a narrower set of use cases.
There are several reasons to use views.
Imagine having an application that is focused on working with data that expires once in a while, such as “trending” blog posts or “active” tasks in an issue tracker. Selecting such data requires filtering, which can be described inside the view. With this approach, the developer is able to work with trending blog posts without concern for how the filtering is implemented. And later the filtering logic may be changed without the need to rewrite all the queries where the view is used.
Another use case is the need to have some calculated value; for example, to subtract VAT from the value of a contract without storing it. Such calculation may be sophisticated, and its implementation can change over time, so having it described in a single place is a good choice.
It is important to note that in some cases, complex calculations are best described in views, not in stored procedures. This way the query interpreter will have better control over the data you need, and the data will be selected more efficiently.
Since regular SQL views are simply “stored” queries, they make use of your database indexes. Moreover, you can add some logic in a query that calls for the view, and for the query interpreter, it will be as simple as an ordinary SELECT query.
Now let us consider an example. We have a blog_post table that looks like this:
CREATE TABLE IF NOT EXISTS blog_post (
id serial PRIMARY KEY,
title text NOT NULL,
body text NOT NULL,
author integer NOT NULL, -- for the sake of example let us omit user table
create_time timestamp,
update_time timestamp
);...and has the following data:
INSERT INTO blog_post (
title, body, author, create_time, update_time
) VALUES
('How I Learned to Stop Worrying and Love the View', 'Text', 1, now(), now()),
('Long article', 'Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum.', 1, now(), now()),
('Another article', 'Text', 1, now() - interval '3 weeks', now() - interval '2 weeks');There are many places in the application that need a short representation of the post's body only of the latest posts. This logic can be implemented like this:
CREATE OR REPLACE VIEW latest_blog_posts AS
SELECT
blog_post.*,
CASE
WHEN length(blog_post.body) > 40
THEN substring(blog_post.body, 0, 40) || '...'
ELSE blog_post.body
END AS body_preview
FROM blog_post
WHERE blog_post.create_time > date_trunc('week', now() - interval '1 week')
OR blog_post.update_time > date_trunc('week', now() - interval '1 week')
ORDER BY create_time DESC;This view selects all the fields of the blog_post table, as well as the new field, body_preview. Note that fields under * will always return all current model fields. When selecting from the view, only the posts created/updated in the last week are returned. The view can be named like this:
SELECT id, title, body_preview, create_time FROM latest_blog_posts;And the output will be:
-[ RECORD 1 ]+-------------------------------------------------
id | 1
title | How I Learned to Stop Worrying and Love the View
body_preview | Text
create_time | 2020-08-10 12:30:00.380537
-[ RECORD 2 ]+-------------------------------------------------
id | 2
title | Long article
body_preview | Lorem ipsum dolor sit amet, consectetur...
create_time | 2020-08-10 12:30:00.380537Since the view is simply a reference to a query, views can be called inside another view. Creating such a “hierarchy” of views is a great way to compose business logic, but one must be careful. With this approach, it is essential to keep views as simple as possible, since a certain view may become a bottleneck for all the views that make use of it. For example:
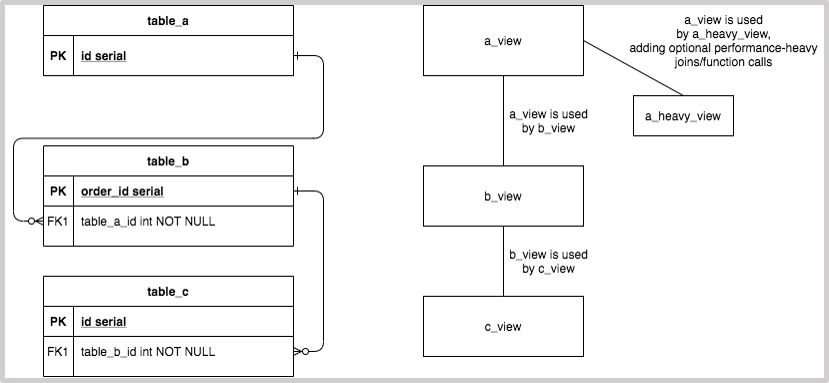
Every table in this diagram has a corresponding view with additional logic. However, there is a need to extend a_view with some additional, heavier joins/function calls. If it is not needed in b_view, it is better to describe another view for table_a containing all the additional logic. This will help to reuse logic from a_view without impacting b_view and c_view.
There is a lot more to SQL views that can be found out here.
Designing and extending a database schema is not an easy task, but keeping these tips in mind makes working with databases painless.
Also, remember that designing a database architecture is not only about the database, but also about the application domain that it implements. A well-researched application domain is already half the battle!
Subscribe for the news and updates
This article demonstrates how to use Python to automate yield calculations in decentralized finance (DeFi), focusing on the Renzo and Pendle platforms. It guides readers through estimating potential rewards based on factors like token prices, liquidity, and reward distribution rules, emphasizing the importance of regular data updates and informed decision-making in DeFi investments.

This article explores how Stoic principles can be applied in the workplace to navigate stress, improve self-control, and focus on what truly matters, with practical examples from the author’s experience in software development.

This article offers key insights into the ISTQB certification and shares a proven preparation strategy to help candidates succeed.

Tired of boring programming courses where you're forced to read thick textbooks and write code that's never used? Need a platform that makes learning fun and exciting? Then you're in the right place!

This article is aimed for beginners, who are trying to choose between Ruby on Rails and Django. Let’s see which is fastest and why.

In this article, we will compare two most popular JS Libraries (Angular vs React). Both of them were created by professionals and have been used in famous big projects.