

Django ORM is a very abstract and flexible API. But if you do not know exactly how it works, you will likely end up with slow and heavy views, if you have not already. So, this article provides practical solutions to N+1 and high loading time issues. For clarity, I will create a simple view that demonstrates common ORM query problems and shows frequently used practices.
Installing django-debug-toolbar
Honestly, I cannot imagine a Django module for ORM requests profiling better than the Django Debug Toolbar. It performs recursive ORM-query request profiling, groups duplicated queries, and returns them to the profiled view.
You can get it here, as well as documentation including installation and configuration instructions.
Creating a common view
Okay, now we have to create an example view. This view fetches 100 users and their groups from the database. I skipped the URL configuration part, as I am sure you can handle it yourself.
from django.shortcuts import render
from django.contrib.auth import get_user_model
User = get_user_model()
def orm_queries_test_view(request):
users = User.objects.order_by("id")[:100]
data = {}
for user in users:
data[user.id] = {
"groups_total": user.groups.count(),
"is_staff": user.groups.filter(name__in=['admin', 'superuser']).exists(),
}
return render(request, "sample/orm_queries_test.html", {"data": data})Now we need a simple template to place django-debug-toolbar in.
orm_queries_test.html :
<html>
<body>
{{ data }}
</body>
</html>Looks pretty simple!
So let’s shoot a request to our test view and check its performance via django-debug-toolbar UI.
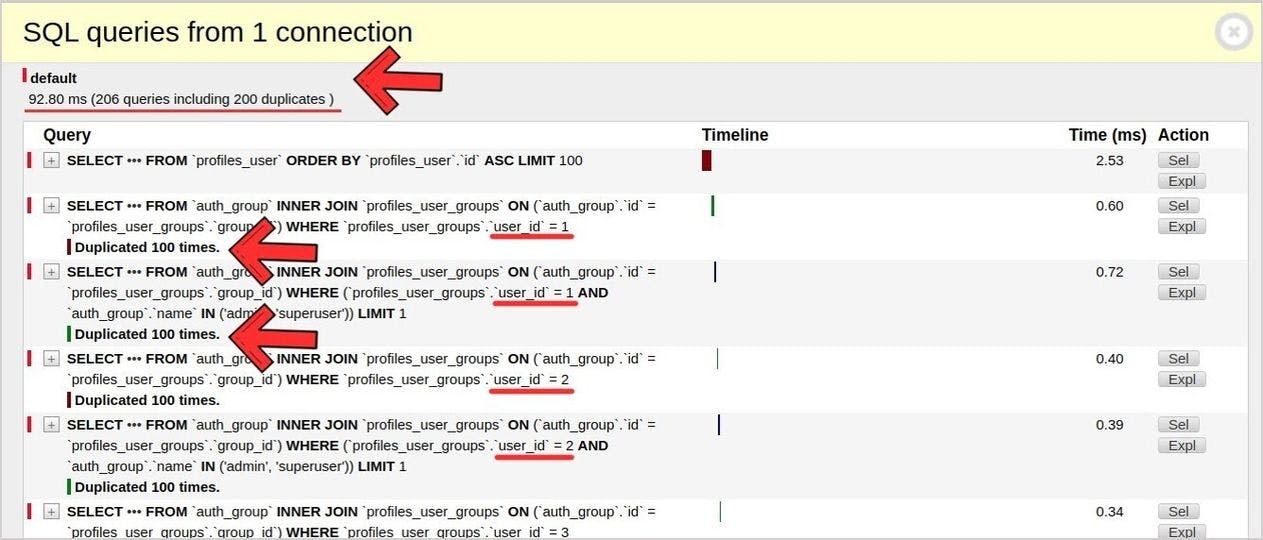
It looks really bad, and we need to understand why this is happening.
As you can see, the ORM has generated many almost equal SQL queries to get users’ groups. Now let’s check one of them.
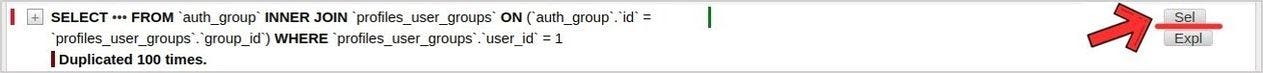

It seems we should use JOIN here, doesn’t it? 😉
The N+1 issue and its solution methods
Using Django ORM, we can instantly get any data from the database anywhere in our code. This is very convenient. But there is a problem if we are fetching a foreign key or many-to-many fields many times in a row.
Just take a look at a simple test below.
from django.db import connection, reset_queries
from django.contrib.auth import get_user_model
User = get_user_model()
def perform_dummy_test(users):
for user in users:
groups = list(user.groups.all())
print('Queries performed:', len(connection.queries))
reset_queries()
users = User.objects.all()[:10]
perform_dummy_test(users)-> Queries performed: 11Whoops! Django ORM cannot implement when and how often we will get additional data from the database in our code. And at this block we fetch users’ groups step-by-step in our cycle, so the ORM generates one request for each iteration to get users’ groups. That is the N+1 issue we are talking about. In this case we can manually preload the required data once and use it as long as we need it.
reset_queries()
users = User.objects.prefetch_related("groups")[:10]
perform_dummy_test(users)-> Queries performed: 2Now we see that one query fetches users and another one fetches their groups.
Nice!
1. Using select_related() and prefetch_related() functions
Django ORM provides two common methods to avoid the N+1 issue, which are select_related and prefetch_related.
The select_related method performs a simple JOIN operation of tables and can be used for foreign key or one-to-one model fields. Prefetch_related works similarly to select_related, but also can obtain many-to-many model fields and uses WHERE expression as an additional condition of the tables JOIN operation.
Okay, let’s try to improve view performance using the prefetch_related method and make a test request to our view.
from django.shortcuts import render
from django.contrib.auth import get_user_model
User = get_user_model()
def orm_queries_test_view(request):
users = User.objects.prefetch_related("groups").order_by("id")[:100]
data = {}
for user in users:
data[user.id] = {
"groups_total": user.groups.count(),
"is_staff": user.groups.filter(name__in=['admin', 'superuser']).exists(),
}
return render(request, "sample/orm_queries_test.html", {"data": data})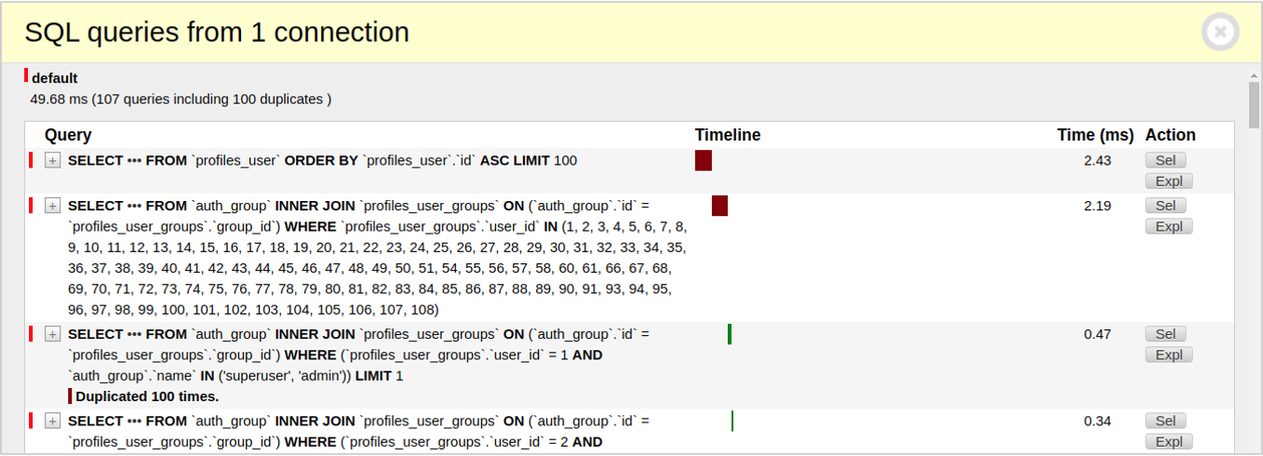
Looks better! But even though we have already prefetched the groups, there are still so many queries performing.
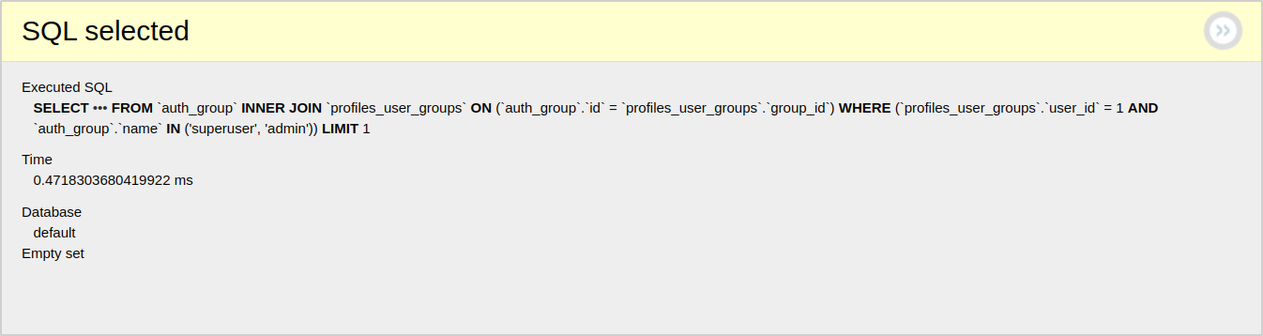
And that is why. When we select the is_staff attribute, the Django ORM generates an additional request that filters groups by name field for every user object in our cycle. So, we should find a way to pre-filter them to avoid the N+1 issue.
2. Using the Prefetch object
The Prefetch object will help us here. This object provides an abstract interface that generates a pre-loaded query. We can combine it with object FK/many-to-many fields. You can imagine it as the intersections of two sets.
So let’s add the Prefetch object to our ORM query to solve the N+1 issue.
from django.shortcuts import render
from django.contrib.auth import get_user_model
from django.contrib.auth.models import Group
from django.db.models import Prefetch
User = get_user_model()
def orm_queries_test_view(request):
staff_groups = Group.objects.filter(name__in=["admin", "superuser"])
users = User.objects.prefetch_related(
“groups”,
Prefetch("groups", to_attr="staff_groups", queryset=staff_groups),
).order_by("id")[:100]
data = {}
for user in users:
data[user.id] = {
"groups_total": user.groups.count(),
"is_staff": len(user.staff_groups) > 0,
}
return render(request, "sample/orm_queries_test.html", {"data": data})Please pay attention: the attribute generated by the Prefetch() object with “to_attr” optional kwarg will be represented as a list instead of a queryset object.
Good! Now it is time to check results.
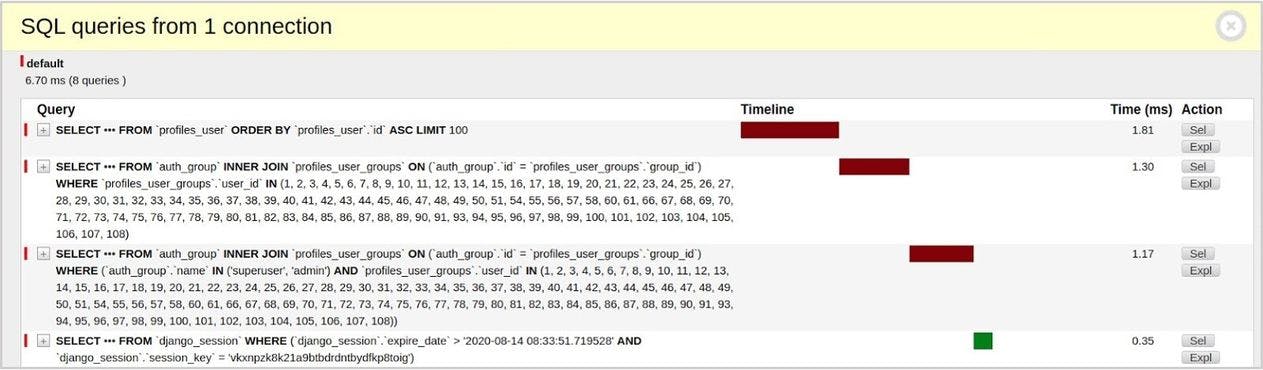
The debug toolbar doesn’t match duplicates now. Finally, we did it!
Adding .only() method for better performance
Django User and Group models are not fat, so we won’t feel a big performance growth in this part of the article. But in case you are using fat models or fields that contain a lot of data, you can easily gain profit just by using this little trick.
The .only() method determines a list of fields to load from the database. Please note, if you use the .only() method and the calling field is not listed, the Django ORM will generate additional requests to get it. So be careful with that.
In our case, we can only get group ids because we do not need other fields of Group model instances.
from django.shortcuts import render
from django.contrib.auth import get_user_model
from django.contrib.auth.models import Group
from django.db.models import Prefetch
User = get_user_model()
def orm_queries_test_view(request):
groups = Group.objects.only('id')
staff_groups = Group.objects.filter(name__in=["admin", "superuser"]).only('id')
users = User.objects.prefetch_related(
Prefetch("groups", queryset=groups),
Prefetch("groups", to_attr="staff_groups", queryset=staff_groups),
).order_by("id")[:100]
data = {}
for user in users:
data[user.id] = {
"groups_total": user.groups.count(),
"is_staff": len(user.staff_groups) > 0,
}
return render(request, "sample/orm_queries_test.html", {"data": data})Let's shoot another test request.
Without .only():

With .only():

Comparing results
Since we have performed some good optimization on our view, it’s time to check the results.
Before:

After:

Duplicates have been removed. Our view makes three SQL queries instead of 201 (the other five are performed by middlewares) and works ~14 times faster!
Looks pretty good! 👍
Testing
It is a good idea to control the number of queries your view performs in tests. Just use the .assertNumQueries method of TransactionTestCase or its inheriting TestCase class as a context manager to make sure your code makes as many queries as you expect
with self.assertNumQueries(2):
Person.objects.create(name="Aaron")
Person.objects.create(name="Daniel")Read more here.
Tips and advice
- The described example is the simplest one I can imagine. In real applications, the source of the problem can be hidden not only in view but also in other application parts, such as a template or serializer. So, please make sure you have checked this too.
- To find slow requests in your project you can use the django-silk module. It provides middleware that logs the queries of every request to the database and has a very friendly UI. It is a good module as a metric system for your project and keeps you up to date on the performance level of your application. You can read more information here.
- Also, you can add the nplusone module to your project. It detects N+1 issues over all ORM requests. This is a good choice if you want to make the perfect ORM request. Read more about the nplusone module here.
- Django ORM stores a data cache of prefetched fields in the _prefetched_objects_cache attribute of a model instance. You can use it, for example, to check that the fields are already prefetched.
hasattr(instance, "_prefetched_objects_cache")Read Also: Trends in SaaS Development
Subscribe for the news and updates
This article explores Figma’s Dev Mode, a tool that streamlines design-to-code translation by enabling precise inspection, automated code generation, and seamless integration with design systems.

In this beginners friends article I'll explain how to make authentication with Google account on your Django site and how to make authentication for you REST API.

Protection of WEB App is of paramount importance and it should be afforded the same level of security as the intellectual rights or private property. I'm going to cover how to protect your web app.

In this article we'll discuss some tricks you can use with Angular to make routing cleaner and improve SEO of your application.

When we use css-sprites it's important to make browser cache them for longest period possible. On other hand, we need to refresh them when they are updated. This is especially visible when all icons are stored in single sprite. When it's outdated - entire site becomes ugly.

In my current project I had a task to use twitter API. Twitter uses OAuth for authentication, which is pretty dreary. To avoid fiddling with it all the time, I've moved authentication to decorator. If key is available - nothing happens, just view is launched as usual. It's convenient that there's no need for additional twitter settings in user profile. Code is in article.