Agile development process
We use an agile workflow, based on Scrum. The workflow is tweaked to let us work effectively in a distributed team, even with the difficulty of working with clients in significantly different time zones.
We use an agile workflow, based on Scrum. The workflow is tweaked to let us work effectively in a distributed team, even with the difficulty of working with clients in significantly different time zones.
We implement projects in small iterations («sprints»). By the end of each sprint we deploy a stable working project to the server.
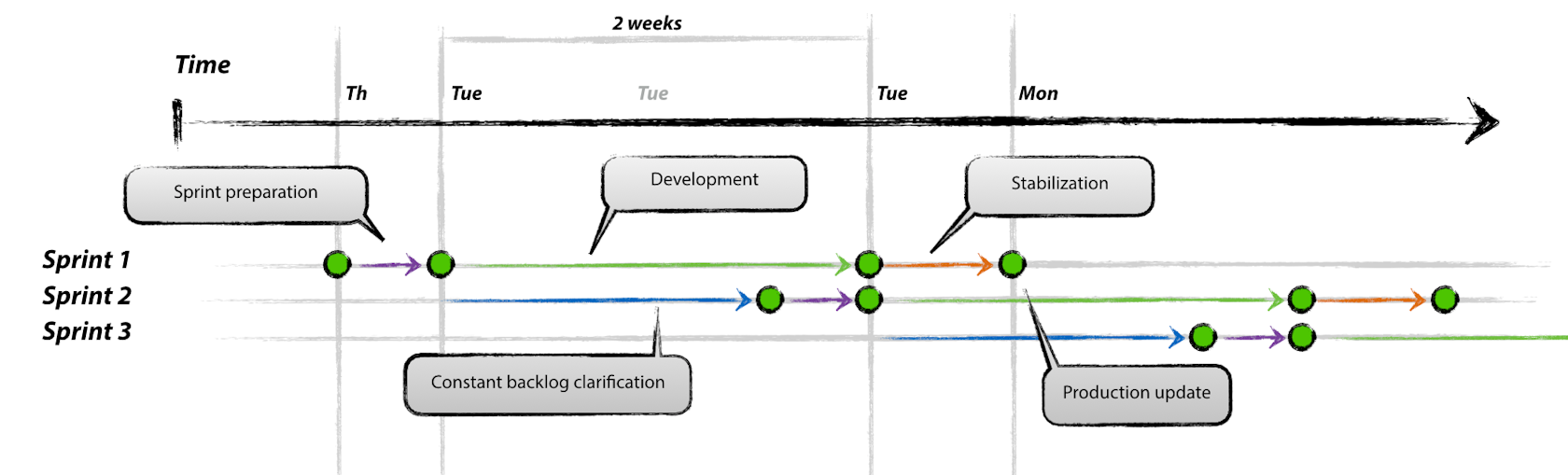
Sprints are either one or two weeks long depending on the project specifics. Duration is fixed and we always deploy the same day*.
Workflow is optimized to ensure that:
- there is a stable product by the end of each sprint
- product concepts can be changed in the middle of the project
- we are never blocked in the middle of the sprint, due to delayed correspondence from the client
- there is no delay in development between the sprints
We use Continuous Integration and follow the git-flow approach in order to manage our repositories.
By the end of each sprint we have a call and demo the project to the client. During the sprint we have short daily calls with a team.
Each project begins with a plan and the creation of a backlog which includes all features that are to be developed.
Sprint phases
Each sprint goes through multiple phases:
- Preparation – describe and estimate tasks
- Development – write code and develop designs
- Stabilization – test and fix bugs
- Deployment – deploy the stable product to the server
During Preparation and Stabilization, the developers’ workload is not constant. Therefore our scheduled sprints overlap in such a way that by the end of one sprint’s development phase, we have already started the next sprint’s development.
Preparation
During the preparation stage, the analyst:
- clarifies with the client, what needs to be done for each task
- prepares a technical description for each task that is enough for full implementation
- verifies that the following resources are ready and available:
- designs
- html/css code
- texts
- estimates various tasks in conventional t-shirt sizes (XS - S - M - L - XL) using historical data engine to predict how much time each task will take. Further information can be found by reading about it in our blog.
- forms a sprint from prepared tasks, making sure that:
- all planned tasks can be accomplished
- developers are fully loaded
- developers are loaded equally
- developers have spare tasks to switch to in case of blockers
- This process continues repeatedly over the course of the project. We split it into separate phases with specified timelines to make sure that upcoming sprints are always prepared on time.
- Phase Input: client’s general explanation of what is required.
- Phase Output: described, estimated and assigned tasks in task management system.
- Responsible parties: analyst, and developers when required.
Development
At the beginning of the development phase, developers split their tasks into subtasks and prepare estimations of the number of hours required. Based on these estimations we can see if we are outside of the original predicted hourly ranges and make adjustments accordingly.
When we complete tasks, developers deploy new features to our development server. QA begins testing those features as they arrive.
During the development phase, developers are rarely blocked on any tasks and don’t require input from the client. On the rare occasion that input is required, we contact the client. Most clients are in a different time zone generating a short lag-time between asking the question and receiving an answer. This is one reason why we prepare multiple tasks for each developer to guarantee that they are kept busy while waiting.
By the end of the development phase developers create a release branch and deploy it to the staging server.
- Phase input: prepared sprint in task manager.
- Phase output: release branch with all implemented features, deployed to the staging server.
- Responsible parties: developers and QA.
Stabilization
Our testing process consists of two parts:
- Individual features are tested during the Development phase. QAs safeguards that the new features are working as required.
- QAs test the entire product during the stabilization phase to make sure that new features did not break anything when they were added.
When bugs are discovered, developers fix them in the release branch and then deploy updates to the staging server.
Sprints overlap in the stabilization phase. QAs do regression testing while developers start working on the next sprint. When bugs are found - developers fix them and switch back to the next sprint.
- Input phase: release branch on the staging server.
- Output phase: stable product on the staging server.
- Responsible parties: QA and Developers.
Deployment
Deployment is not really a phase, it is more of a joyful event. It is worth mentioning because deployment is our ultimate goal.
Hot fixes
It would be suspicious if we told you that everything always goes according to plan. Sometimes there are situations that require us to fix something in production immediately regardless of our sprint phase or even sleep phase.
When this happens, we create a small ad-hoc sprint that runs parallel to the current sprint.
Any new feature is implemented on top of the current production code (not the current development branch) and is pushed to the staging server for testing. When testing is completed - we deploy a hot fix to production and merge it to the development branch.
Hot fixes are usually small and don’t require any changes in the current sprint, but from time to time we may have to move low-priority tasks to the following sprint.
Integration with the client’s team
We often work with a client’s existing team, but we still prefer to follow our workflow.
This collaboration works best when we are given a separate section of the project which saves on coordination efforts. We prefer to avoid projects where our developers are directly managed by the client’s personnel.
Working with external providers
We work with external providers for: designs, mobile applications, HTML/CSS coding and other services. Our workflow does not conflict with our partners’ processes in any way. We schedule our work in such a way that we always have externally-provided materials ready before sprint starts - this way we don’t have to coordinate and micro-manage our tasks during the week.
Roles
We have the following roles in our workflow: Analyst, Developer, QA. Some management work is required, especially when we have to coordinate with external teams. We don’t have a designated manager, instead an Analyst or a lead Developer takes care of the management tasks.
Task management system
We built our own task management system and we use it on all of our projects. It allows us to schedule sprints, predict task durations, and track time. It also features a user friendly client UI that permits clients to monitor their project in real time.
Sometimes clients have to use Jira, Trello, Asana or another system for their projects. In these cases we use our system, but sync data with the client’s system.
Repository management
We use git for all of our projects. Recently we’ve migrated to GitLab, but prior to that we were using Bitbucket. Git is a very flexible tool, but in order to use it efficiently with a team, it requires some conventions. We follow the famous git-flow approach, which matches our workflow perfectly.
Continuous integration
We’ve used different combinations of Jenkins, TeamCity, Fabric and Ansible scripts. Today we use GitLab’s continuous integration system on all of our projects.
If for some reason we cannot use GitLab, our fallback is Jenkins.
DESCRIBED WORKFLOW PROVES TO BE OF GREAT ASSISTANCE IN KEEPING PROJECTS ON TIME FOR OUR CLIENTS. CONTACT US IF YOU HAVE ANY IDEAS ON HOW TO IMPROVE THIS WORKFLOW OR IF YOU HAVE ANY OTHER QUESTIONS.
The article highlights common test case mistakes, offers ways to fix them, and provides practical tips to improve and optimize test cases.

This article explores Figma’s Dev Mode, a tool that streamlines design-to-code translation by enabling precise inspection, automated code generation, and seamless integration with design systems.

This article demonstrates how to use Python to automate yield calculations in decentralized finance (DeFi), focusing on the Renzo and Pendle platforms. It guides readers through estimating potential rewards based on factors like token prices, liquidity, and reward distribution rules, emphasizing the importance of regular data updates and informed decision-making in DeFi investments.

This article explores how Stoic principles can be applied in the workplace to navigate stress, improve self-control, and focus on what truly matters, with practical examples from the author’s experience in software development.
